Task Scheduling
3 minute read
How does the scheduling work in Oakestra?
Oakestra’s architecture is composed of two tiers. Resources are divided into clusters. A cluster is seen as the aggregation of all its resources. A job is first scheduled to a cluster, and then the cluster scheduler decides the target worker.
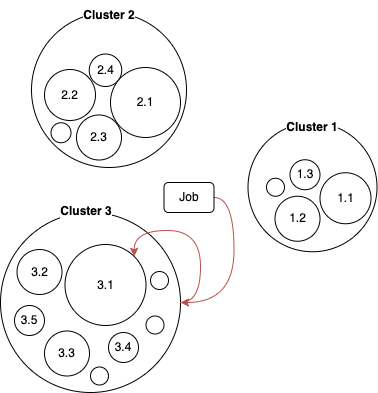
The scheduling component is as simple as a Celery worker. The scheduler receives a job description and gives back an allocation target. We differentiate between the Root scheduler and Cluster scheduler. The Root scheduler finds a suitable cluster (step 1), and the Cluster scheduler finds a suitable worker node (step 2).
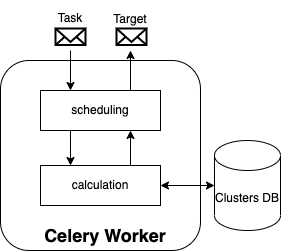
This scheduling algorithm does not ensure an absolute optimal deployment but consistently reduces the search space.
Scheduling Algorithm
At each layer, the scheduling decision consists of the creation of a candidate_list of clusters (or workers), the exclusion of unsuitable candidates, and then the selection of the “best” candidate accordingly to a scheduling algorithm.
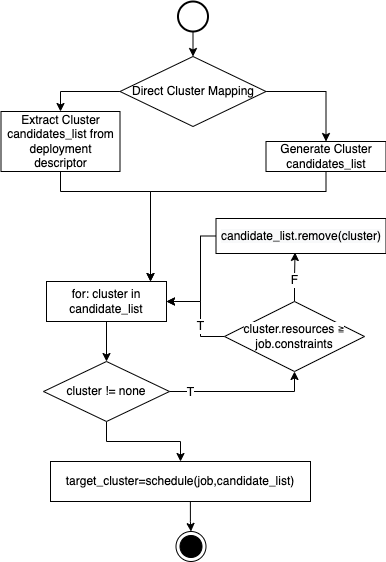
The scheduling algorithms are implemented in the calculation.py component of each respective scheduler.
The current released version only implements a best fit and first fit calculation strategies. However, on its way to the release, we have our new LDP algorithm (check it out on our whitepaper).
Job Constraints
The Job deployment descriptor allows a developer to specify constraints of 4 types: node resources, network capabilities, geographical positioning, and direct mapping.
Resources
The job resource requirements cause the immediate exclusion of a candidate from the candidate list. These resources represent the bare minimum required by the job to operate properly. Here there is a table of the supported resources and the state of development:
| Resource type | Status | Comments |
|---|---|---|
| Virtualization | 🟢 | Fully functional containers support. Unikernel support is under development. |
| CPU | 🟢 | Only number of CPU cores |
| Memory | 🟢 | Memory requirements in MB |
| Storage | 🟠 | It is possible to specify it, but it is not yet taken into account by the scheduler |
| GPU | 🟠 | Possibility of specifying the GPU cores. But not yet the available GPU drivers. Right now, the support is only for CUDA. |
| TPU | 🔴 | Not yet under development |
| Architecture | 🔴 | Not yet possible to filter out the architecture. With containers, it is possible to use the multi-platform build. This flag is coming out together with the Unikernel support. |
Network & Geo constraints
The networking requirements selection and geographic constraints support are coming out in our next release v0.5 and are part of the LDP algorithm update. Stay tuned.
Direct mapping positioning
It is possible to specify a direct mapping constraint. Therefore, in the deployment description, a developer can specify a list of target clusters and nodes. The scheduling algorithm operates only on the active clusters (or nodes) among the given list.
This direct mapping approach is currently based on cluster names and worker hostnames. We are anyway considering adding a label-based positioning where it is possible to tag resources with custom-defined labels. Stay tuned for more.