High level architecture
Categories:
4 minute read

Table of content
Oakestra Detailed Architecture
As shown in our Get Started guide, Oakestra uses 3-4 building blocks to operate.
- Root Orchestrator
- Cluster Orchestrator
- Node Engine
- NetManager (optional, detailed in the networking section of the Wiki)
This section of the wiki is intended for people willing to contribute to the project and it is meant to describe some internal architectural details.
Root Orchestrator
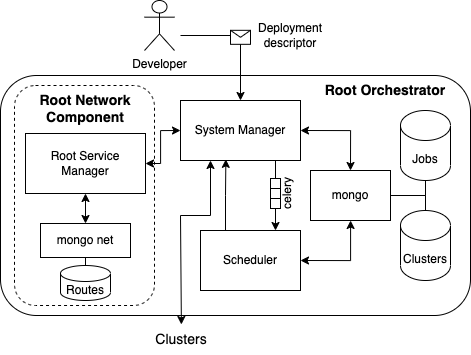
The Root Orchestrator is a centralized control plane that is aware of the participating clusters.
This picture describes the containers that compose the Root Orchestrator. As you may have seen we use docker-compose to bring up the orchestrators. This is because each block of this picture is currently a separated container.
- The System Manager is the point of contact for users, developers, or operators to use the system as an application deployment platform. It exposes APIs to receive deployment commands from users (application management) and APIs to handle slave Cluster Orchestrators. Cluster Orchestrators send their information regularly, and the System Manager is aware of those clusters.
- The scheduler calculates a placement for a given application within the available clusters.
- Mongo is the interface we use to access the database. We store aggregated information about the participating clusters. We differentiate between static metadata and dynamic data. The former covers the IP address, port number, name, and location of each cluster. The latter can be data that is changing regularly, such as the number of worker nodes per cluster, total amount of CPU cores and memory size, total amount of disk space, GPU capabilities, etc.
- The Root Network Components are detailed in the Oakestra-Net Wiki.
System Manager APIs
At startup, the System Manager exposes the public APIs at <root_orch_ip>:10000
Thr API documentation is available at <root_orch_ip>:10000/api/docs
Consideration regarding failure and scalability:
The main problem of a centralized control plane is that it can act as a single point of failure. By design without a Root Orchestrator, the clusters are able to satisfy the SLA for the deployed applications internally, the only affected functionalities are the deployment of new services and the intra-cluster migrations. To avoid failure and increase resiliency, an idea is to make the component able to scale by introducing a load balancer in front of the replicated components. However, this feature is not implemented yet.
Cluster Orchestrator
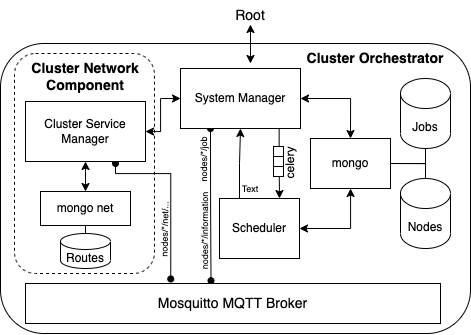
The Cluster orchestrator is a twin of the root but with the following differences:
- The cluster orchestrator’s scope is the end worker node devices.
- A cluster orchestrator performs aggregation. It aggregates the worker node resources and does not expose the cluster composition directly to the root.
- The cluster uses MQTT for communication with the worker nodes.
MQTT Topics
The topics used to interact with the worker nodes are:
- “nodes/
/information$”: topic where each worker periodically posts its resources usage - “nodes/
/job$”: used to perform deployments on a worker node and receive back the feedback - “nodes/
/jobs/resources$”: used to post the resource usage and status of the running instances in a worker node
Schedulers Algorithms
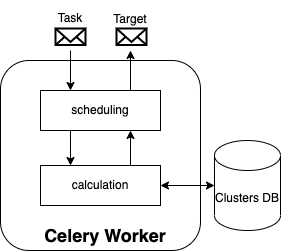
The schedulers, at each level, receive Job Placement tasks and return a placement decision. At the root level, the placement decision is a Cluster. At the cluster level, the placement decision is a worker node.
A job placement task is a Job structure composed of:
- Service
- Instances
- Requirements
Placement currently uses the default Best Fist algorithm. You can find more details in the scheduling section of the wiki.
Worker Node
A machine, in order to be qualified as Worker Node, must contain a Node Engine and optionally a Net Manager. The former enables the deployment of applications accordingly to the runtimes installed. The latter plugs the networking components to enable communication across the applications deployed.
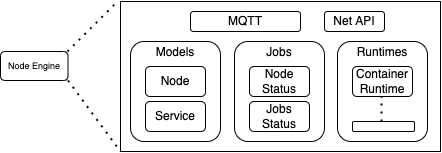
The Node Engine is a single binary implemented using Go Lang and is composed of the following modules:
- MQTT: This is the interface between the worker and the Cluster. The deployment commands, node status updates, and jobs updates use this component.
- Models: This contains the models that describe the node and the jobs.
- Node: describes the resources of the node that are transmitted to the cluster. This is decomposed into dynamic resources and static. The status of static resources is transmitted only at startup. Dynamic resource statuses such as cpu/memory usage are updated regularly.
- Service: describe the fields of the services that are managed by this implementation of the worker node, as well as the real-time service usage statistics that must be monitored.
- Jobs: Background jobs that monitor the status of the Worker node itself and the applications deployed.
- Runtimes: Contains the glue with the supported system runtimes. Right now, the runtime dispatcher only supports containerd and, therefore, “containers” is the only runtime available. Any new runtime integration is implemented here. We’re currently working on Unikernels integration.